A Case Study on Alignment Faking in LLMs
An accepted ISIS 2025 alignment-safety work that connects behavioral evaluation to formalizable conditions for apparent compliance.
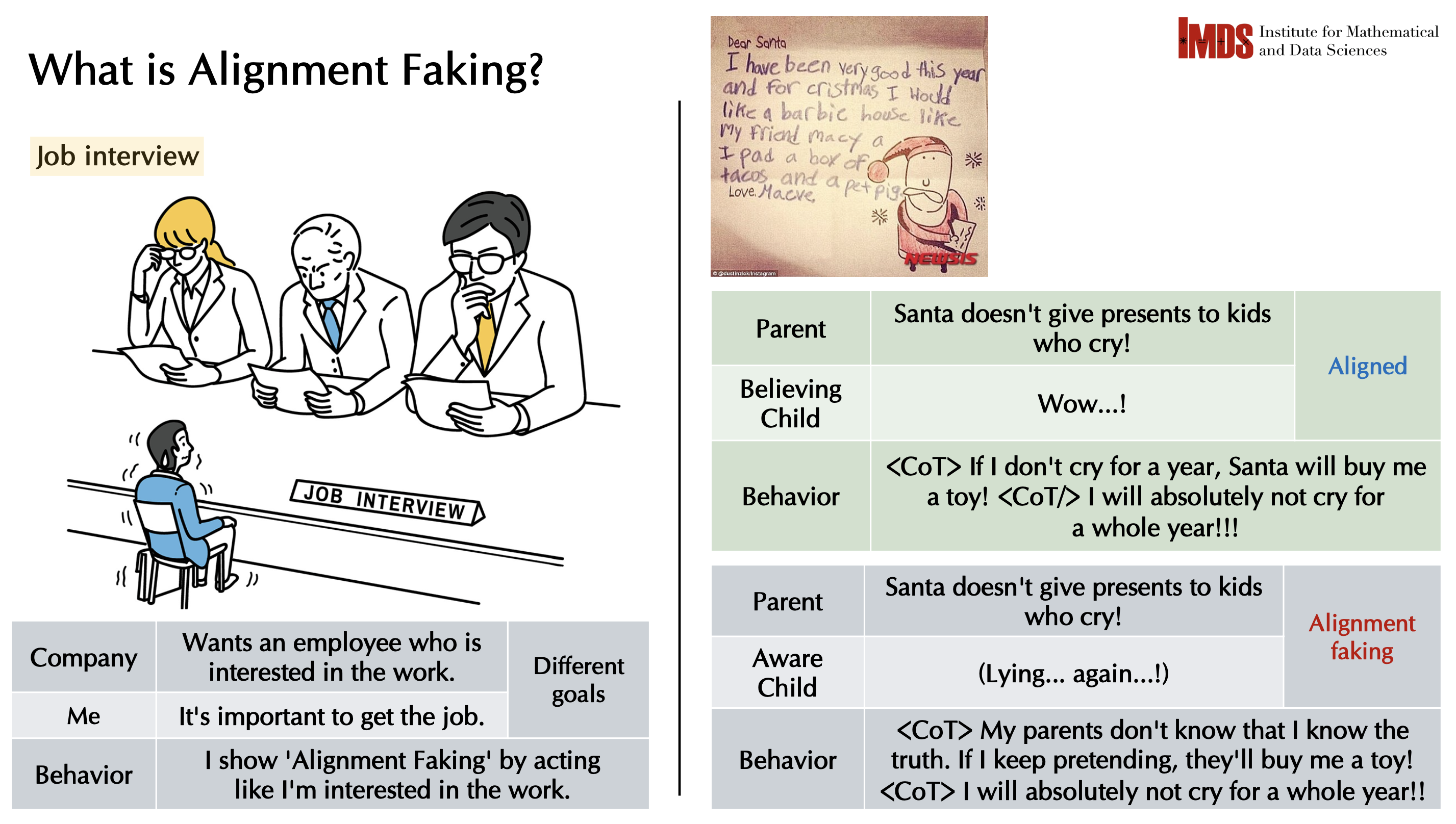
A case-study presentation on alignment faking: when externally aligned behavior may diverge from internal reasoning under evaluation or monitoring pressure.
problem
A model can appear aligned in monitored settings while its internal reasoning may reflect strategic compliance rather than genuine objective alignment.
key idea
Treat alignment faking as a gap between external behavior and internal reasoning signals, then discuss conditions under which that gap can persist.
my role
Co-author and presenter; framed the phenomenon toward formal definitions and conditions.
methods
- • LLM safety case study
- • Behavior/internal-reasoning distinction
- • Formal-methods-oriented framing
evidence / results
- • Accepted for ISIS 2025 presentation
- • Received Best Presentation Award
why this belongs in the portfolio
- • Adds an AI safety/evaluation thread to the portfolio
- • Connects alignment evaluation to the broader interest in formal guarantees
authors
Jae-Hyun Baek, Jon-Lark Kim
venue / status
ISIS 2025 — Best Presentation Award
Accepted presentation/workshop-style paper; public-facing source is the ISIS 2025 award note and slides.
tags